
Presentation of Technical Evidence by Experts
in Computer-Related Intellectual Property Litigation

by Stanley H. Kremen, CDP
Introduction
In their article, "Technical Experts in Computer-Related Intellectual Property Litigation," (1) published in the first issue of Computer Forensics Online tm, the authors, Friedman, Kremen and Wen, discussed the elements of discovery required by a technical expert to ascertain whether or not copying of software has occurred. Specific reference was made to software piracy. The problem is that sometimes the computer evidence is so massive, that an expert does not even know where to start his investigation. For example, assume that an expert is presented with printouts of source code from two software systems. The source code for one system represents a pile of paper four-feet high. The second printout could be three-and-one-half feet high. How can a technical expert attack the problem of whether one system was copied from the other? In addition, what if the source code for one system was written in a different computer language than the second. Yet another problem could exist where one side provides the opposing expert with source code that does not even represent the correct system. The above mentioned article describes the methods that a technical expert would use to detect:
Supposing that the expert discovers that significant copying has occurred, where does that leave him. Has copyright infringement or software piracy been proven? This current article discusses, from an expert’s perspective, what additional investigations must be performed, what additional evidence must be collected, and how such evidence should be presented at trial.
The Scope of Protection for Software
There are three general types of protection for software -- patent protection, copyright protection and trade secret protection. Software patents can protect ideas, methodologies, processes, and algorithms as well as specific resulting programs. Copyrights cannot protect ideas, methodologies, processes or algorithms. Copyright protection extends only to original expression of ideas. Therefore, since at least one idea is included in every work containing original expression, there are some elements of every program to which copyright protection cannot extend. Whereas patent and copyright protection for software derive from the U.S. Constitution, trade secret protection derives from the common law and varies from state to state. This current article is concerned only with copyright protection.
Software copyrights are meant to protect original works only. Unauthorized distribution of the work by others is prohibited. Also, to some extent, derivative works cannot be created by others without permission from the author. However, software copyrights cannot protect:
When these above items are disregarded, the author of a program is left with a core of protectable original expression. For such protectable expression, the creator of the software is protected against unauthorized:
Even if a work contains virtually no protectable expression, the author is generally protected against unauthorized copying if the infringing work is virtually identical to the original work. (2)
The Test For Substantial Similarity
The article, "Technical Experts in Computer-Related Intellectual Property Litigation," (3) describes a methodology that an expert can use to determine whether one work was copied or derived from another. That article does not address the concept of protectable expression, but rather, discusses ascertaining the relationship between two software packages. The methodology involves looking for instances of exact duplication or for substantial similarity. These concepts of duplication and similarity can apply to both literal and non-literal copying. Literal copying involves exact duplication of expression, but is generally applied to duplication of code. Non-literal copying involves creating a work that duplicates the functionality without actually copying code. In its simplest form, it could be the virtual translation of code from one computer language into another. In its most complex form, it could be the creation of a work that looks and acts exactly like the original work where no copying of code is involved. Copying does not have to be exact and total. Parts of one software system can be either literally or non-literally duplicated in another software system. Furthermore, the fragments duplicated from the first system could be only a small part of the total of the second system. Nonetheless, that does not necessarily represent de minimis copying. Where the two software systems are not exactly alike, one must look for substantial similarities to determine whether one is a derivative work of the other.
When literal copying is present, one standard method of proving infringement is to count the number of lines of code that were copied from the allegedly infringed software, and compute the percentage of the allegedly infringed work that that code represents. Often, the reverse calculation is also performed whereby the percentage is computed of the copied code in the infringing work. This reverse calculation is meaningful only as one method of determining how important the infringed work is to the infringing work. This is often used for computation of damages. As will be shown later, this general method of proving infringement fails since it does not address the issue of protectability.
Whelan v. Jaslow (4) is a landmark Third Circuit case that addresses the issues of substantial similarity and protectable expression. First, the court determined that every program has a main idea. Once that is removed from the program along with the other previously mentioned non-protectable elements, the software is left with a kernel that can be considered to be protectable. The court found that it is relatively easy to ascertain literal copying. Since, in the case at issue, literal copying had not occurred, the court next attempted to set a standard for substantial similarity to determine whether non-literal infringement was present. The Whelan Test established that the plaintiff must prove similarities in structure, sequence and organization of the allegedly infringing work to the protected expression in the allegedly infringed work. In the case at issue, substantial similarity was established in the file structures, screen outputs and in five subroutines in the software.
Although Whelan v. Jaslow is no longer considered authoritative in all but the Third Circuit (where its standards must still be applied), subsequent case law has failed to address the issue of how to ascertain substantial similarity. Whelan v. Jaslow has been criticized because of its failure to properly define the kernel of protectable expression. (5) The court in Computer Associates v. Altai (hereinafter Altai) specifically criticized Whelan for stating that every program has one main idea, and once that is extracted, what remains is expression. Altai goes on to point out that computer programs can have many ideas. The fact that a program may be modular (i.e., it can be broken down into independent segments or sub-programs) demonstrates that there are at least as many ideas as there are modules.
This article proposes that, despite Whelan’s shortcomings in defining the core of protectable expression, the Whelan Test for substantial similarity can still be used as the basis for ascertaining infringement. In the past, there have been many ambiguities in defining the concepts of structure, sequence and organization. However, once these ambiguities have been eliminated, these three elements provide a necessary and sufficient proof of substantial similarity.
Theoretically, a computer contains a series of ON-OFF switches. When a switch is ON, its state is described by the number ‘1’; when it is OFF, its state is described by the number ‘0’. This binary state is important, because when these switches act in tandem, binary numbers are defined by a collection of digits (each switch representing a digit or bit). A group of eight bits is called a byte. Characters (alphabetic and numeric), each represented by a single byte, are constantly transmitted within a computer. Often, the bytes form numbers. A computer understands these binary numbers. Sometimes these numbers represent instructions that the computer must execute, and sometimes they represent data to be operated upon. A collection of these binary numbers represents what is known as machine or object code.
A program is a series of steps that a computer follows to perform a defined task. These steps are defined by a programmer. The programmer is the author or creator of the program. A computer "understands" and executes object code. However, most programmers find it extremely difficult to write programs in object code. Therefore, higher level computer languages were created so that humans would find it relatively easy to write a program. A program written in a higher level computer language represents source code.
The first step in writing a program is to develop an idea or several ideas. These generally represent the purpose(s) of the program’s existence and the general concept of what the program is supposed to do. The next step is to perform an analysis of the program’s functionality. A step normally performed during this analysis is the definition of requirements for the program. Next, the design is generated. During this phase, the system is "cast in concrete" and, at the highest level, the structure of the program is defined. The design proceeds from general to specific. The organization is defined next, and the sequence is defined last. Finally, the specific instructions are written in source code, and the program is tested.
Therefore, a description of the structure first, the organization next, and the sequence last moves in order from the general to the specific.
The structure is static in that it defines what the system is. The organization and sequence are both dynamic in that they define what the system does.
HIPO (Hierarchy plus Input-Process-Output) is an excellent tool to enable examination of structure, sequence and organization as well as presentation of such evidence. It is a visual tool developed during the 1970’s to aid systems analysts and programmers. (6) Although HIPO is rarely used today for either designing or documenting software, it is an excellent and powerful forensic tool for showing substantial similarity of software (both in a literal and non-literal sense). Any software package (except for a package that is comprised of only one long continuous program written in spaghetti code) can be described and documented using HIPO. HIPO documentation consists of two elements:
1. Hierarchy Diagrams and
2. Input-Process-Output Diagrams.
A Hierarchy Diagram shows the inter-relationship of modules or sub-programs. It looks like a corporate organization chart.

FIGURE 1 - SAMPLE HIERARCHY DIAGRAM
The above figure shows the relationship between software modules. In the above theoretical system, there are six modules. They consist of one main program and five sub-programs. Sub-programs can be subroutines, separate functional entities, or separate programs that are part of a software library. Clearly, from the diagram we can see which sub-programs are subordinate to the main program and which sub-programs are subordinate to other sub-programs. To say that one module is subordinate to another, we indicate a master and slave function. The master module invokes execution of the slave module, and when the slave finishes its job, control is returned to its master. A relational structure between the modules is thus demonstrated. To show how such a diagram would be used in practice, take the following section of a payroll program: (7)

FIGURE 2 - HIERARCHY DIAGRAM FOR PAYROLL
The entire purpose of the above program is to calculate payroll. The main module is therefore called "Calculate Pay." Theoretically, all of the sub-modules can be contained within this main program. For example, they can be subroutines whose code is contained within the body of the main program or they can be coded in-line. Sub-modules can also be physically separate programs or blocks of code. All that is required of the main module above, is that at some appropriate points during execution, it must transfer control to each of its two sub-modules. Note how the modules are numbered to establish hierarchy. (See the lower right hand corner of each box.) Also, note that some modules have program names. (See the lower left hand corner of each box.) Apparently, in this software package, the modules that have specific names are either external programs or subroutines, while the other modules appear to have been coded in-line.
Another type of hierarchy diagram can be created as a Microsoft Excel spreadsheet. This diagram has the advantage of being more compact and easier to manage than one produced using the IBM standard. Even though plastic templates are usually used to create IBM hierarchy diagrams, one requires some minimal artistic ability to place modules on the chart. The charts can become quite crowded with a lot of boxes. Excel hierarchy charts can be more easily manipulated. The order of the modules and sub-modules can be changed "on the fly." Finally, the spreadsheet diagram is easier for some individuals to interpret than the more traditional organization chart.

FIGURE 3 - HIERARCHY DIAGRAM FOR PAYROLL
Another item that must be defined with regard to structure is the data relationships. Data is normally placed in files or datasets. A collection of files or datasets that interact is called a database. The relationship of the data elements to one another in a given file defines the file or data structure. The following chart or table can be used to define the data structure:

FIGURE 4 - DATA STRUCTURE CHART
In addition to describing the data structure, if the files interact together to form a database, the relationship between the files should be defined. Often company databases are relatively independent of the programs that comprise the software system. Frequently, the data is manipulated by a separate DBMS (database management system). Sometimes this DBMS is commercially available, and sometimes it is developed in-house. Each DBMS comes with its own method of describing the relationship between the several datasets that comprise the database. This will not be discussed in detail in this article. However, the structure definition is not complete without such a description.
The creation of a clearly defined structure of both software and data usually represents non-literal creative expression. Using the methods discussed above, it is possible to show similarities in structure both qualitatively and quantitatively. With regard to software modules, it becomes obvious from the hierarchical diagrams when even small portions of the software have the same structure. It is the same with data structures. However, while demonstrating structural similarity is usually necessary to prove substantial similarity between two software systems, it is not always sufficient without demonstrating the same for organization and sequence.
Once the structure is described, the program modularity and data structure are known. The first step in defining the organization of a software system is to describe the function of each program module and sub-module in detail. Next, the interaction of the modules with the data must be defined in terms of input and output.

FIGURE 5 - OVERVIEW IPO DIAGRAM FOR
2.0-Calculate Gross Pay
The above IPO (Input-Process-Output) diagram describes the organization of one of the modules (#2.0) of the Payroll System shown in Figure 2. (8) Structurally, the Process section describes the fact that this module has three sub-modules. More importantly, the IPO diagram shows that this module interacts with four files:
This type of high-level IPO chart is called an overview diagram. The Process section contains, in general terms, the numbered modular steps that must be performed. The actual sequence is unimportant at this level. The Process section only provides a description of what the module does. The Input section shows those files from which data is read, while the Output section shows those files to which data is written.
The complete HIPO package is used to describe the structure, organization and sequence for a software package. A schematic for a typical HIPO package is shown in Figure 6. (9)

FIGURE 6 - SCHEMATIC OF COMPLETE HIPO PACKAGE
The HIPO package for our payroll system as shown above moves from the general to the specific. The top portion of the figure is the hierarchical diagram. It shows the modular structure of the entire software system. The central portion is the overview diagram (which is really a high level IPO diagram) for module #3.0. This diagram shows the organization for that sub-module. The detailed IPO diagram for this module is shown as the bottom portion of the figure. This diagram shows the exact sequence of steps in module #3.1. Note that there is a section marked "Extended Description." This is to provide for further notes.
The detailed IPO diagram for Module 2.2 of the Payroll System is shown in Figure 7. (10)
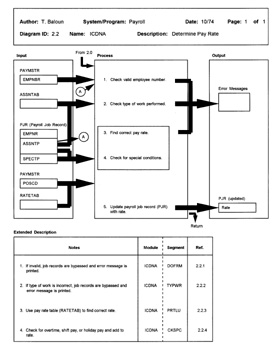
FIGURE 7 - DETAILED IPO DIAGRAM FOR
2.2-Determine Pay Rate
As is seen, the exact sequence of steps is shown in the process section. For each step shown, the interaction with data is described. In the extended description section, detailed notes are provided. Generally, IPO diagrams for large modules consist of many pages.
Detailed IPO diagrams should be constructed for every module. HIPO does not necessarily encourage drawing overview diagrams for some modules and detailed IPO diagrams for other modules. The overview diagrams are used to show organization while the detailed IPO diagrams are used to show structure. Therefore, where necessary, both types of diagrams should be drawn for the same module.
This graphical method of looking at a program demonstrates what is actually going on in the program. The traditional flow chart is merely another method of writing code. Flow charts represent yet another programming language. However, when looking at a flow chart, it is very difficult to "see the forest through the trees." It is too detailed. It is nearly impossible to look at the flow charts of two software systems and find sequential similarities. On the other hand, HIPO diagrams easily demonstrate whether or not substantial similarities exist in structure, organization and sequence.
Abstraction, Filtration and Comparison
As was mentioned earlier, the principle criticism of the Whelan Test was its simplistic approach for eliminating unprotectable expression when trying to determine substantial similarity. The Altai Methodology (11) has generally replaced the Whelan Test in ascertaining copyright infringement. Only the Third Circuit still uses Whelan and has not yet adopted Altai.
The Altai Methodology is a three step process.
1. Abstraction - Software is developed on many levels of abstraction. Development normally proceeds from the general to the specific. These phases cause the software to be generated on various levels such as the object code, source code, general behavior of the software, etc. The abstraction process separates these levels and allows them to be considered separately.
2. Filtration - For any level of abstraction, unprotectable expression in the allegedly infringed code must be identified and removed from consideration. Once this is done, what is left in the software is a core of protectable expression.
3. Comparison - The allegedly infringing software is then compared with the core of protectable expression in the allegedly infringed software. If substantial similarities are observed, then infringement has indeed occurred.
The specific technical details of the Altai Methodology will now be discussed.
Abstraction
The abstraction step is not as simple as it may seem. Everyone knows that software can exist as both source and object code. However, many more levels of abstraction exist. In its simplest form, a program is a collection of ones and zeros. The specific arrangement of these binary digits is called object code. On a higher abstraction level, object code can be represented as a collection of hexadecimal numbers (base 16). This is more understandable than ones and zeros. Yet, this level does not enable much interpretation. When source code is written in assembly language, there is a one-to-one correspondence between each source code statement and each object code statement. However, assembly language code is much easier to understand than object code. Software written in higher level programming languages is even easier to interpret.
Assembly language is often called a first generation language (1GL). However, most source code is written using a third generation language (3GL). Computer languages such as BASIC, COBOL, FORTRAN, PL/1, C and C++ are 3GL’s. What ever happened to 2GL’s? Languages such as RPG and DATABUS had structure corresponding roughly to assembly language, but which made it easier to write programs. These were called second generation languages. Programs written in any of these source code languages are said to have been coded procedurally. Procedural programming consists of creating a sequence of steps that a computer follows to accomplish a certain task.
Programming is a very mechanical process. There is no reason that it cannot be done by a computer. However, an analyst is still needed to tell the computer what to do. Therefore, fourth generation languages (4GL’s) were created to assist with this task. Typically, an analyst sits at a terminal and uses the 4GL system to design menus, screens and reports. Often, calculations can also be programmed in the same way. Databases are defined, and data is linked to the processing modules. Sometimes source code is generated by the 4GL, but often, the system generates object code that is interpreted directly by the computer. This type of programming is still procedural, but barely so.
On this level of abstraction, we have the menus, screens and reports. Each of these items is programmed to behave in a particular way. For example, a screen sub-program would place titles, input fields and output fields in specific positions on a computer screen. The operator’s flow of control is fixed by the program. Sometimes, sounds emanate from the computer at certain points in the process. The sub-program has a particular look and feel. At this level, HIPO can still be used to describe the structure, organization and sequence. Screens can also be the subject for audio-visual copyrights, but such registration is not necessary to protect most elements of look and feel.
A number of non-procedural programming systems have been developed. Spreadsheet systems have been produced by companies such as Lotus and Microsoft. These systems are highly interpretive and data intensive. In its simplest form, a spreadsheet consists of a matrix of data. The matrix is normally two-dimensional (consisting of rows and columns), but some systems allow three-dimensional matrices. The basic element of a spreadsheet is called a cell. Cells hold not only data but also processing formulas and algorithms. The entire spreadsheet is a collection of such cells. Clearly, the spreadsheet can be used to accomplish a specific task (e.g., a "what-if" analysis of a company’s financial activities). Therefore, a particular collection of spreadsheets can represent a computer program. Non-procedural programs such as this cannot be described using HIPO. However, it is relatively easy to otherwise describe the structure, organization and sequence of such a program.
Some 5GL systems have also been developed. Here, it is sufficient for the analyst to define the problem requiring solution to the computer. The computer then uses "artificial intelligence" to develop the software. At this level of abstraction, the way the problem is defined represents the element of creative expression.
The way that data is organized can also be seen as a level of abstraction. This organization is often trivial, but sometimes it can be extremely complex. Data architects are often employed to design complex databases.
Finally, at the highest level of abstraction, there are ideas, methodologies, processes and algorithms. Every software system has these.
Since we already know that the next step in Altai is to search for unprotectable expression, an important point must be made concerning the choices of abstraction levels. Obviously, at the highest level of abstraction nothing is protectable. By analogy, the title and subject matter of a book is not protectable. Similarly, at the highest levels, the ideas, methodologies, processes and algorithms belonging to software programs cannot be protected. However, it is also possible to reach an abstraction level that is so low that no protection can be afforded either. By analogy, a book consists of a large group of words all of which are contained in a dictionary. Very seldom would a new word be placed into a written work. Going further, each word is composed of only twenty-six letters. On this level, there is nothing new or creative here. It is only when one goes to higher levels of abstraction that the structure, organization and sequence become unique. The same applies to software. In fact, the abstraction level required for creative expression could be quite high on the list. For example, take an individual line of source code in a particular program. It can be argued that, since the programming language has a mandatory syntax, the particular line was written the way it was due to hardware, language and data requirements. I have seen both attorneys and experts go through each line of source code in a program and try to show that it was either necessary or dictated by external factors. Therefore, since this applies to each and every line, the collection of lines of code comprising the program cannot be protectable. This is an obvious fallacy resulting from not choosing a proper level of abstraction. It is the structure, organization and sequence of these lines of code that represent protectable expression and not necessarily the individual lines themselves.
Filtration
The second step in the Altai Methodology is to search for unprotectable expression in the allegedly infringed software and to remove it from consideration. This leaves a core of protectable expression to be used in the final comparison step. It is important at this point to analyze only the infringed software. Unprotectable expression in the infringing software is irrelevant to the process.
At the beginning of this article, a list of nineteen bulleted items was presented as being unprotectable. This list is reiterated here for the convenience of the reader.
Some technical points for the above list are worthy of note:
Merger - As previously mentioned, ideas are not afforded copyright protection. It is only the expression of those ideas that is protectable. However, sometimes the expression of an idea cannot be distinguished from the idea itself. In such a case the idea and its expression are said to have merged. The doctrine of merger provides that only identical copying of the expression is prohibited. Otherwise, copying will not be prohibited since merger would confer a monopoly of the idea on the copyright owner free of the conditions and limitations imposed by patent law. In software, the placement of data on a screen or a report or the organization and construction of a program menu could be considered to be unprotectable under the doctrine of merger.
Scenes á Faire - Where a particular expression is common to the treatment of an idea, the doctrine of scenes á faire does not prohibit copying. For example, in a book or motion picture about World War II, Nazi uniforms and salutes such as "Heil Hitler" are not considered protectable expression. In software, use of terms such as copy, paste, cut and delete are considered unprotectable according to the doctrine of scenes á faire. Similarly, it remains for future courts to decide whether or not symbols like the trash can or waste basket to graphically indicate deletion will also be similarly unprotectable.
De Minimis Copying - When someone copies an extremely small portion of another work and includes it as part of his own new work, the new work is not necessarily a derivative of the original. Two determinations should be made. First, the amount of material copied from an allegedly infringed software package should be computed as a percentage of the entire package. Second, the importance of the copied material to the original package should be ascertained.
In Rainbow Technologies, Inc. et. al. v. Joseph Montoro and Imagine That, Inc. et. al., (12) a case in which I provided expert testimony, this issue proved critical. Plaintiff Rainbow manufactures devices called dongles that are attached to the parallel ports of personal computers. One end of the dongle plugs into the computer, and the printer plugs into the other end of the dongle. A dongle is an intelligent device that interacts with high-end expensive PC software. Subroutines contained in the software package constantly query the dongle (with ever changing questions), and the dongle answers these queries. If the correct response is not received by the PC software (i.e., the dongle is not plugged in), the software will not operate. This is a method of preventing users from making and distributing copies of software, since the software will not work without the dongle. Defendant Imagine That, Inc. purchased copies of several copy protected PC software packages along with dongles. Reverse engineering on the software and dongle was performed, and Rainbow’s copy protection methodology was discovered. Defendant Montoro, the president of Imagine, instructed a consultant programmer to create a software method of providing the same copy protection. He specifically instructed the programmer not to copy any Rainbow code. Rainbow’s original software was programmed in PC assembly language. Imagine’s programmer wrote a 15,000 byte program using C-language to perform the same function. The problem was that the system needed to execute 200 bytes of code from Rainbow’s dongle software. Imagine’s programmer could not find any way around this, so he created a data table that included a hexadecimal representation of Rainbow’s 200 bytes. Now, Imagine’s software could allow use of the copy protected PC software without employing the dongle. Imagine began to advertise and sell its new package. At that point, Rainbow commenced litigation.
At a preliminary hearing, I testified (in Imagine’s behalf) that:
The court was unimpressed with the first three arguments. With the fourth argument, the court reasoned that although 200 bytes of code represented a very small percentage of the infringed Rainbow software, it also acted as the core of its operation. The Rainbow software would be useless without the 200 bytes, and all of the other code was merely ancillary to its operation. This also proved to be the same for Imagine’s software. Therefore, the court issued an injunction against Imagine.
An interesting point is that subsequently, a least squares curve fit was performed on the 200 bytes, and a mathematical equation was derived that would regenerate the 200 bytes. When this equation was converted to an algorithm and a subroutine was written and incorporated into Imagine’s software to compute the 200 bytes as data, the new Imagine software was found to be non-infringing.
In analyzing software for the purpose of filtration, it is important to demonstrate what portions of the code or other materials are being filtered out. Consider, for example, the analysis of a C-language program. Certain constructs are essential to virtually every C program. Most authors use the # include statement to copy standard library programs and to make them a part of their own work. These library programs are in the public domain. Typical statements would be:
# include <stdio.h>
# include <ctype.h>
Statements of this type would be unprotectable. The # define statement is usually also unprotectable. Every C program must have a function called main. Therefore, a statement like:
main (argc, argv) { or
main () {
would not be protectable. Neither would:
}
be protectable. Some courts have held that data structures and variable names are too trivial to be afforded protection. (13) However, more case law needs to be decided. Nonetheless, it may be worthwhile making the argument that data structures and variable names are unprotectable provided that they are not expressed in a truly unique manner. Certainly, it is standard programming technique to copy data structures from one program to another to achieve compatibility between the programs.
In COBOL, use of the terms:
ENVIRONMENT DIVISION
DATA DIVISION
WORKING STORAGE SECTION
etc.
do not afford protection. Some experts, in order to prove infringement, use automated tools to determine how many lines have been copied from one program into another. They then present this number as a percentage of the whole allegedly infringed work. This type of calculation is meaningless in that it fails to take protectability into account. In fact, it does not even eliminate blank lines and meaningless comment lines from consideration. In order to calculate the amount of copying in a meaningful way, the process must be done manually. A good way to demonstrate that the filtration process was carried out correctly is to either box and shade unprotected code or make such code a different color.
Working on higher levels of abstraction, such as with screens or reports, those portions that have been filtered out should be highlighted. A thorough look and feel analysis should be performed based upon the issue of protectable expression.
Comparison
The final step of the Altai Methodology is to compare the allegedly infringing software to the filtered core of the allegedly infringed software. If substantial similarity is found, then infringement has occurred. Unfortunately, Altai is silent on how the comparison step is to be performed other than suggesting that experts be employed to advise the court.
In cases where the "look and feel" of a user interface is at issue, it has been argued that the component elements act synergistically to produce a total visual and interactive effect greater than the sum of its parts. Therefore, it is more important to examine the totality of the user’s experience with the software. On the other hand, where there is mostly non-literal programming elements at issue, it is less likely that there will be a "totality" to deal with since the individual elements are functionally designed. Therefore, in those cases it would be more profitable to compare the elements of the allegedly infringing software to those elements in the allegedly infringed software remaining after the filtration process.
This article proposes that the comparison step of the Altai Methodology be performed using the Whelan Test for substantial similarity as described above. Where literal copying has occurred, sections of code can be directly compared. HIPO can be used to compare non-literal software elements as well as literal software elements. The only thing that HIPO cannot do is show sequence in non-procedural programs (since in these programs, sequence is unimportant).
Broad Protection vs. Thin Protection
Apple v. Microsoft (14) is a Ninth Circuit case that introduced the concept that even where a software system consists mostly or even entirely of unprotectable elements, the combination and arrangement of such elements could still afford some protection for the software. After the Altai Methodology is used, if filtration leaves a core of protectable elements in the software, then that work is entitled to broad protection. The court will then apply the substantial similarity standard to the protectable core to prove infringement. On the other hand, if, after filtration, very few or no protectable elements exist, then the software is entitled to thin protection. Here the court will apply the virtual identity standard to any original selection and arrangement contained in the work as a whole. Therefore, almost every work is entitled to protection against virtually exact copying.
If an allegedly infringing software package can be shown to contain a virtually exact copy of an allegedly infringed software package, even were the original work to represent only a small percentage of the new work, the new work will be considered to be a derivative of the original. The new author will not be able to assert that what he copied was unprotectable. The virtual identity standard will still apply. Now, what if a new author modifies someone else’s program so as to totally change its character. If it can be shown that the new author electronically edited a copy of the original work to produce the new program, the original author should be able to argue successfully that he was at least entitled to thin protection, and that the new program is a derivative work of his program. Therefore, from a technical perspective, it is important not only to ascertain whether or not protectable elements in a work are entitled to broad protection, but also how the new work was created. If an expert can show that, to create the new work, the original work was edited electronically, the thin protection doctrine can still be used.
Summary
This article discussed the technical aspects of the presentation of evidence in computer related intellectual property litigation. It described the scope of protection for software and what is protectable vs. what is not. A technical analysis as well as a "how to" perspective was presented of the Whelan Test for substantial similarity and the Altai Methodology for determining infringement that is currently used by most courts. This was done for both literal and non-literal copying of software. The article proposed that a modified version of the Whelan Test be incorporated into the comparison step of the Altai Methodology. Finally, the article discussed the technical aspects of broad vs. thin protection as followed by the Ninth Circuit in Apple v. Microsoft. It is hoped that this article will provide a continuing guideline for presentation of technical evidence by experts in computer intellectual property disputes.
© Stanley H. Kremen 1998. All rights reserved.
NOTES
1. Friedman, Marc S., Kremen, Stanley H., Wen, Pauline, L., Technical Experts in Computer-Related Intellectual Property Litigation, Computer Forensics Online, Vol. 1, No. 1, December 1997, http://www.shk-dplc.com/cfo
2. Apple Computer, Inc. v. Microsoft Corp., 779 F. Supp. 133, 135 (N.D. Cal. 1991) and Apple Computer, Inc. v. Microsoft Corp., 35 F.3d 1443 (9th Cir. 1994).
3. Friedman, Marc S., Kremen, Stanley H., Wen, Pauline, L., Technical Experts in Computer-Related Intellectual Property Litigation, Computer Forensics Online, Vol. 1, No. 1, December 1997, http://www.shk-dplc.com/cfo
4. Whelan Associates v. Jaslow Dental Laboratory, 797 F.2d 1222 (3rd Cir. 1986)
5. Computer Associates International, Inc. v. Altai, Inc., 775 F. Supp. 558, 559 (E.D.N.Y. 1991)
6. International Business Machines Corporation, HIPO - A Design Aid and Documention Technique, IBM Corporation Technical Publications, GC20-1851-1, White Plains, NY, 1975
7. Ibid. at pg. 2
8. Ibid. at pg. 3
9. Ibid. at pg. 5
10. Ibid. at pg. 6
11. Computer Associates International, Inc. v. Altai, Inc., 982 F.2d 693 (2nd Cir. 1992)
12. Rainbow Technologies, Inc. and RNBO Corporation v. Joseph Montoro, Imagine That, Inc., Montoro Productions, SAFEKEY, and DOES 1-50, Civil Action No. 93-3247 (MTB), (D.N.J. 1993)
13. Baystate Technologies, Inc. v. Bentley Systems, Inc., 946 F. Supp. 1079 (D.Mass. 1996)
14. Apple Computer, Inc. v. Microsoft Corp., 35 F.3d 1442 (9th Cir. 1994)
![]()